Linux内核地址映射模型
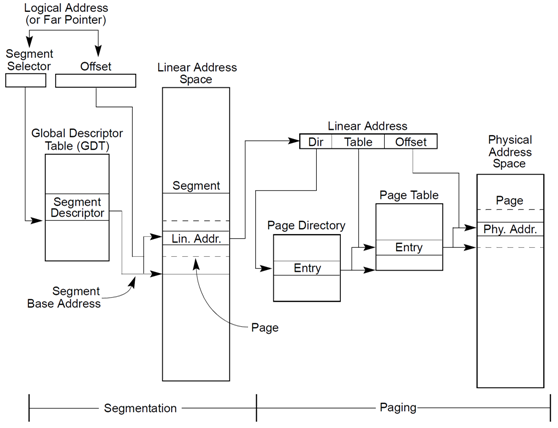
x86 CPU采用了段页式地址映射模型。进程代码中的地址为逻辑地址,经过段页式地址映射后,才真正访问物理内存。
段页式机制如下图。
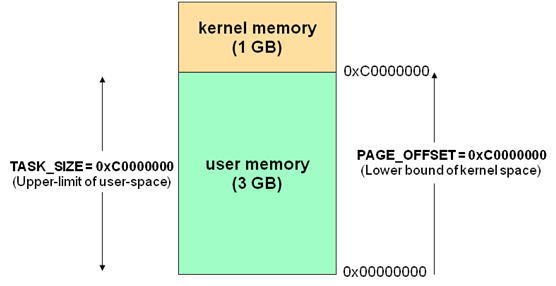
Linux内核地址空间划分
通常32位Linux内核地址空间划分0~3G为用户空间,3~4G为内核空间。注意这里是32位内核地址空间划分,64位内核地址空间划分是不同的。
Linux内核高端内存的由来
当内核模块代码或线程访问内存时,代码中的内存地址都为逻辑地址,而对应到真正的物理内存地址,需要地址一对一的映射,如逻辑地址0xc0000003对应的物理地址为0x3,0xc0000004对应的物理地址为0x4,… …,逻辑地址与物理地址对应的关系为
物理地址 = 逻辑地址 – 0xC0000000
| 逻辑地址 | 物理内存地址 |
| 0xc0000000 | 0x0 |
| 0xc0000001 | 0x1 |
| 0xc0000002 | 0x2 |
| 0xc0000003 | 0x3 |
| … | … |
| 0xe0000000 | 0x20000000 |
| … | … |
| 0xffffffff | 0x40000000 ?? |
假设按照上述简单的地址映射关系,那么内核逻辑地址空间访问为0xc0000000 ~ 0xffffffff,那么对应的物理内存范围就为0x0 ~ 0x40000000,即只能访问1G物理内存。若机器中安装8G物理内存,那么内核就只能访问前1G物理内存,后面7G物理内存将会无法访问,因为内核的地址空间已经全部映射到物理内存地址范围0x0 ~ 0x40000000。即使安装了8G物理内存,那么物理地址为0x40000001的内存,内核该怎么去访问呢?代码中必须要有内存逻辑地址的,0xc0000000 ~ 0xffffffff的地址空间已经被用完了,所以无法访问物理地址0x40000000以后的内存。
显然不能将内核地址空间0xc0000000 ~ 0xfffffff全部用来简单的地址映射。因此x86架构中将内核地址空间划分三部分:ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM。ZONE_HIGHMEM即为高端内存,这就是内存高端内存概念的由来。
在x86结构中,三种类型的区域如下:
ZONE_DMA 内存开始的16MB
ZONE_NORMAL 16MB~896MB
ZONE_HIGHMEM 896MB ~ 结束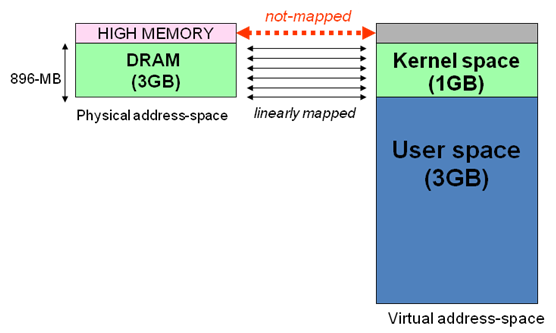
Linux内核高端内存的理解
前面我们解释了高端内存的由来。 Linux将内核地址空间划分为三部分ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM,高端内存HIGH_MEM地址空间范围为0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)。那么如内核是如何借助128MB高端内存地址空间是如何实现访问可以所有物理内存?
当内核想访问高于896MB物理地址内存时,从0xF8000000 ~ 0xFFFFFFFF地址空间范围内找一段相应大小空闲的逻辑地址空间,借用一会。借用这段逻辑地址空间,建立映射到想访问的那段物理内存(即填充内核PTE页面表),临时用一会,用完后归还。这样别人也可以借用这段地址空间访问其他物理内存,实现了使用有限的地址空间,访问所有所有物理内存。如下图。
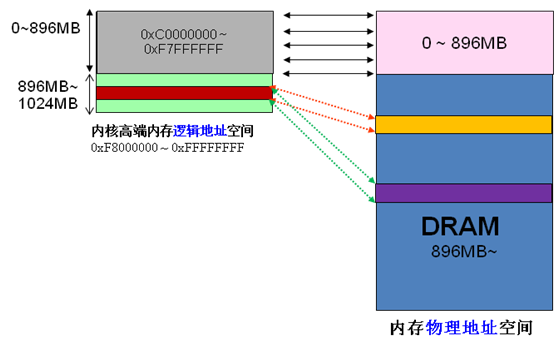
例如内核想访问2G开始的一段大小为1MB的物理内存,即物理地址范围为0x80000000 ~ 0x800FFFFF。访问之前先找到一段1MB大小的空闲地址空间,假设找到的空闲地址空间为0xF8700000 ~ 0xF87FFFFF,用这1MB的逻辑地址空间映射到物理地址空间0x80000000 ~ 0x800FFFFF的内存。映射关系如下:
| 逻辑地址 | 物理内存地址 |
| 0xF8700000 | 0x80000000 |
| 0xF8700001 | 0x80000001 |
| 0xF8700002 | 0x80000002 |
| … | … |
| 0xF87FFFFF | 0x800FFFFF |
当内核访问完0x80000000 ~ 0x800FFFFF物理内存后,就将0xF8700000 ~ 0xF87FFFFF内核线性空间释放。这样其他进程或代码也可以使用0xF8700000 ~ 0xF87FFFFF这段地址访问其他物理内存。
从上面的描述,我们可以知道高端内存的最基本思想:借一段地址空间,建立临时地址映射,用完后释放,达到这段地址空间可以循环使用,访问所有物理内存。
看到这里,不禁有人会问:万一有内核进程或模块一直占用某段逻辑地址空间不释放,怎么办?若真的出现的这种情况,则内核的高端内存地址空间越来越紧张,若都被占用不释放,则没有建立映射到物理内存都无法访问了。
在香港尖沙咀有些写字楼,洗手间很少且有门锁的。客户要去洗手间的话,可以向前台拿钥匙,方便完后,把钥匙归还到前台。这样虽然只有一个洗手间,但可以满足所有客户去洗手间的需求。要是某个客户一直占用洗手间、钥匙不归还,那么其他客户都无法上洗手间了。Linux内核高端内存管理的思想类似。
Linux内核高端内存的划分
内核将高端内存划分为3部分:VMALLOC_START~VMALLOC_END、KMAP_BASE~FIXADDR_START和FIXADDR_START~4G。
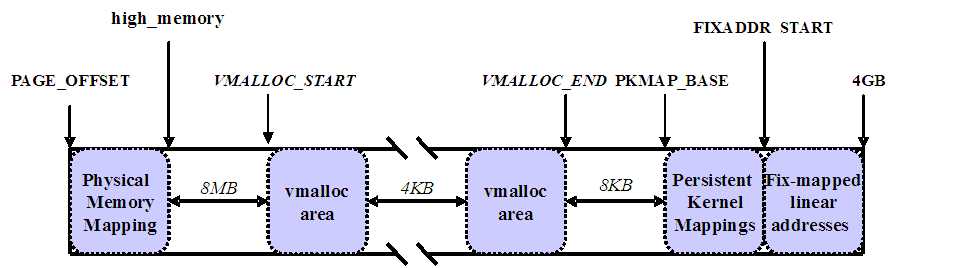
对于高端内存,可以通过 alloc_page() 或者其它函数获得对应的 page,但是要想访问实际物理内存,还得把 page 转为线性地址才行(为什么?想想 MMU 是如何访问物理内存的),也就是说,我们需要为高端内存对应的 page 找一个线性空间,这个过程称为高端内存映射。
对应高端内存的3部分,高端内存映射有三种方式:
映射到”内核动态映射空间”(noncontiguous memory allocation)
这种方式很简单,因为通过 vmalloc() ,在”内核动态映射空间”申请内存的时候,就可能从高端内存获得页面(参看 vmalloc 的实现),因此说高端内存有可能映射到”内核动态映射空间”中。
持久内核映射(permanent kernel mapping)
如果是通过 alloc_page() 获得了高端内存对应的 page,如何给它找个线性空间?
内核专门为此留出一块线性空间,从 PKMAP_BASE 到 FIXADDR_START ,用于映射高端内存。在 2.6内核上,这个地址范围是 4G-8M 到 4G-4M 之间。这个空间起叫”内核永久映射空间”或者”永久内核映射空间”。这个空间和其它空间使用同样的页目录表,对于内核来说,就是 swapper_pg_dir,对普通进程来说,通过 CR3 寄存器指向。通常情况下,这个空间是 4M 大小,因此仅仅需要一个页表即可,内核通过来 pkmap_page_table 寻找这个页表。通过 kmap(),可以把一个 page 映射到这个空间来。由于这个空间是 4M 大小,最多能同时映射 1024 个 page。因此,对于不使用的的 page,及应该时从这个空间释放掉(也就是解除映射关系),通过 kunmap() ,可以把一个 page 对应的线性地址从这个空间释放出来。
临时映射(temporary kernel mapping)
内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为”固定映射空间”在这个空间中,有一部分用于高端内存的临时映射。
这块空间具有如下特点:
(1)每个 CPU 占用一块空间
(2)在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个 page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的 km_type 中。
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。通过 kmap_atomic() 可实现临时映射。
常见问题:
1、用户空间(进程)是否有高端内存概念?
用户进程没有高端内存概念。只有在内核空间才存在高端内存。用户进程最多只可以访问3G物理内存,而内核进程可以访问所有物理内存。
2、64位内核中有高端内存吗?
目前现实中,64位Linux内核不存在高端内存,因为64位内核可以支持超过512GB内存。若机器安装的物理内存超过内核地址空间范围,就会存在高端内存。
3、用户进程能访问多少物理内存?内核代码能访问多少物理内存?
32位系统用户进程最大可以访问3GB,内核代码可以访问所有物理内存。
64位系统用户进程最大可以访问超过512GB,内核代码可以访问所有物理内存。
4、高端内存和物理地址、逻辑地址、线性地址的关系?
高端内存只和物理地址有关系,和线性地址、逻辑地址没有直接关系。
5、为什么不把所有的地址空间都分配给内核?
若把所有地址空间都给内存,那么用户进程怎么使用内存?怎么保证内核使用内存和用户进程不起冲突?

写的很不错~~
总结的比较全面~~谢谢分享!
写的太清晰,明了啦,一看便懂啊。谢谢哈,看完之后醍醐灌顶啊。
4、高端内存和物理地址、逻辑地址、线性地址的关系?
高端内存只和逻辑地址有关系,和逻辑地址、物理地址没有直接关系。
==================应该是高端内存只和线性地址有关系吧?
逻辑地址经过段式映射后,才为线性地址,而线性地址对代码是透明的。因此高端内存只和逻辑地址有关。
根据millerixlee兄弟的提醒,更正一下:高端内存和物理内存地址有关。
“因此x86架构中将内核地址空间划分三部分:ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM。”
我不太同意博主的以上说法。据ULK内存管理章节介绍可知:内存管理区的划分是针对物理内存的,不是针对内核的虚拟地址空间的。(ULK 英文版 p303:memory zones)
非常感谢指正。:-)
内存区域划分确实是针对物理内存的,稍后我修改一下。
如果内核只能访问前1G内存,那用户进程可以访问1G以上的物理内存么
内核可以访问所有物理内存。在32位系统中,用户进程可以访问3G物理内存,64位系统中,用户进程可以访问512G以上物理内存。
用户进程访问的物理地址范围,是由内核指定的。
这里“在32位系统中,用户进程可以访问3G物理内存”的意思是不是可以理解为用户进程分配的内存都存在于高端内存?
内核给用户进程分配的物理内存,和高端内存没有关系。若机器只有512MB内存,内核会一样保证用户进程正常使用内存。
高端内存的概念起源于内核态访问物理内存,和用户态/用户进程无关。
高端内存源于32Bit的限制,64Bit就没有高端内存,作者对这块还没有弄清楚
请问在64位系统中,如果内核空间没有了高端内存的概念,那vmalloc所分配的内存对应的物理内存可以在所有位置?
vmalloc()在有高端内存存在时,也是可以申请到非高端内存部分的内存。64位系统一样存在高端内存概念,只是物理内存容量很少达到1TB,此时就没有高端物理内存存在。我们有的客户会配置1.5TB甚至2TB物理内存,用普通的Linux内核,内核里就会存在高端内存。
好的,明白了,非常感谢。
有没有地方可以向你咨询一下内存屏障方面的问题? 我一直没有搞的很清楚。 比如在NUMA系统中,在一个core上更新变量,是不是一定要用smp_wmb才能刷新cache,其它core才能看到?
你的很多文档都写的非常好,清晰易懂,我都下载了,谢谢。 关于内存屏障方面有没有类似的文档?
这些文档主要内容都是6、7年前写的,这几年工作更多关注硬件之上的业务,没写内核系列的文章。前几年写的好有内核I/O系列的文档,现在没时间重新整理发布。
有篇内存屏障的文章写的还可以。http://ifeve.com/linux-memory-barriers/
64位Linux系统,不是0XFFFF 8800 0000 0000 ~0XFFFF C7FF FFFF FFFF直接映射物理内存吗?这个空间总共有64TB,那么如果计算机不按照超过64TB的内存,理论上就不应该有高端内存的问题吧。
是的。你的理解很准确。
好的,非常感谢。
非常好的文章,解释清楚很多问题,学生党,学习驱动开发中,看了三天关于内存与IO访问的内容,网上这样的精致的文章不多。多多和楼主学习!
感谢好文。请教两个问题:
1. 保护模式下的内存访问指令里都是虚拟地址吧,0~896MB的那部分映射怎么能绕得过MMU的页表翻译呢?是怎么实现的加减一个offset就得到物理地址的呢?
我看内核里似乎就是真的直接加减一个offset得到物理地址。我很奇怪,为什么会用得到物理地址呢?指令里的地址都是虚拟地址,我替MMU算出物理地址有什么用?最后岂不还是得MMU替我做转换?
2. “为什么不把所有的地址空间都分配给内核?若把所有地址空间都给内存,那么用户进程怎么使用内存?怎么保证内核使用内存和用户进程不起冲突?”
为什么内核和用户进程会起冲突呢?从用户态切换到内核态时换一套页表不就好了?
3. 页表这类数据都保存在哪里?那1个G的内核空间里?我总觉得会不会这1G空间不够啊,尤其是系统里的进程比较多的时候。
感谢。
1、保护模式下,任何内存访问指令都需要经过MMU。内核的虚拟地址和物理地址,减去一个offset,是因为内核初始化时,已设置好地址映射目录/页面表,让地址转换刚好是一个offset。
2、可以让用户态和内核态共享一个页面表,但这样用户态程序岂不是可以随意读写内核态的数据?内核安全性得不到保证。
3、页表保存在内存中,内核初始化时会设置内核内存映射页面表,用户态程序使用时,Page Fault时会建立映射表。页面表占用空间为 (物理内存大小/4K)*sizeof(struct page)。
建议抽空看一下这两篇文档,并做实验验证,会让你清晰了解地址映射过程。
http://ilinuxkernel.com/?p=1276
http://ilinuxkernel.com/?p=1303
2. 我就是不要”用户态和内核态共享一个页面表”,而是分别有一套页表啊… 我觉得这样似乎可以做到”把所有的地址空间都分配给内核”,而且用户态程序也不会干扰到内核,只要把这两套页表小心地设置好。
3. “页表保存在内存中”,是的。我的意思是,从虚拟地址的角度来说,包含页表数据的页是保存在1G的内核空间里呢,还是保存在3G的用户空间里?我想应该是1G的内核空间吧?那么,一般是保存在3G ~ 3G + 896M这部分里呢,还是保存在3G + 896 ~ 4G这部分里?还是都可以?
感谢回复。
1、用户态和内核态分别有一套页表,是否意味着同一段物理地址是不是都可以被用户态和内核态同时访问?若都能访问,还是涉及读写冲突问题。这样的设计肯定是有问题的。
2、页面表通常是放在物理地址靠前的地方。
BTW,在这个文档 http://ilinuxkernel.com/files/Linux_Physical_Memory_Description.pdf 里提到,x86-64的系统如果只有4GB物理内存,则所有内存属于ZONE_DMA32, 而ZONE_NORMAL为空。
我在实际系统里查看了下,物理内存4GB的机器,实际上ZONE_NORMAL并不为空。似乎有个误区,Linux里物理内存分区的大小实际只是上限,并不是实际的分配大小。譬如X86的ZONE_DMA为16MB,这个理解应该是上限为16MB,并不是实际分配的就是16MB。内核里的注释似乎也说明了这点,如下
/*
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* Architecture Limit
* —————————
* parisc, ia64, sparc <4G
* s390 <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
请把你在物理内存4GB机器上的内存信息贴上来,看一下。谢谢。
dzhao2x@dzhao2x-desktop:~/yeyanyan/others/scripts/flash_key$ sudo cat /proc/pagetypeinfo
[sudo] password for dzhao2x:
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 1 1 0 0 2 1 1 0 1 0 0
Node 0, zone DMA, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Movable 0 0 0 0 0 0 0 0 0 0 3
Node 0, zone DMA, type Reserve 0 0 0 0 0 0 0 0 0 1 0
Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Unmovable 7 1 7 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Reclaimable 13257 8398 6466 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Movable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Reserve 0 0 0 1 1 1 1 1 1 1 0
Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Unmovable 1486 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Reclaimable 241 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Movable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Reserve 0 0 24 20 7 0 0 1 1 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Reclaimable Movable Reserve Isolate
Node 0, zone DMA 1 0 6 1 0
Node 0, zone DMA32 54 447 1281 2 0
Node 0, zone Normal 52 118 68 2 0
dzhao2x@dzhao2x-desktop:~/yeyanyan/others/scripts/flash_key$ uname -a
Linux dzhao2x-desktop 3.5.0-23-generic #35~precise1-Ubuntu SMP Fri Jan 25 17:13:26 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
dzhao2x@dzhao2x-desktop:~/yeyanyan/others/scripts/flash_key$ sudo cat /proc/meminfo | grep Total
MemTotal: 4006692 kB
SwapTotal: 4151292 kB
VmallocTotal: 34359738367 kB
HugePages_Total: 0
高端内存HIGH_MEM地址空间范围为0xF8000000 ~ 0xFFFFFFFF(896MB~1024MB)
你这不对啊, 0xFFFFFFFF是4GB啊
128MB高端内存来映射其他物理内存, 那么同时只能最多使用128MB的其他内存??
你好,想问下如果在64位机器上(内存16G)用alloc_page加上__GFP_HIGHMEM标记,那申请到的页是在哪块内存空间?理论上不应该有高端内存吧?但这样申请的页要获取线性地址依然需要用到kmap函数。但ext文件系统的数据页的mapping默认都有__GFP_HIGHMEM标记?
感谢您写的这篇文章,使我明白了highmem是什么!!在明白后,发现其实这是一个很简单的问题,但在我看到您的文章之前,搜了很多其它highmem相关的文章,没有一篇能讲明白的。我读完您的文章后,也仔细的看了您对每一条评论的回复,看您回答评论问题也是非常的详尽。祝好!
谢谢。
因此x86架构中将内核地址空间划分三部分:ZONE_DMA、ZONE_NORMAL和ZONE_HIGHMEM。
这里应该是将”物理地址空间“分为三部分
有些地方是错的,用户空间看到的地址都是虚拟地址不会是物理地址,最后一段话写错了
博主半吊子啊, 高端内存指的是物理内存, 内核如果直接映射1G物理内存, 就无法通过线性地址直接访问高于1G的物理内存, 所以抽出128M的内核地址空间用作映射高端内存。 关于进程的高端内存问题, 进程运行所需的物理内存, 对进程本身是不感知的, 进程使用的是线性地址,但是进程的物理内存是否是高端内存, 这取决于内核的机制, 如果内核normal内存运行, 也可以从normal内存中分配, 当然也可以从高端内存分配。
ps: 直接访问的概念指的是在内核中直接通过线性地址访问(在normal内存以下, 物理地址就是线性地址), 高端内存与896M以上线性地址没有建立一一对应的固定映射关系, 不是直接访问。
欢迎交流。
第三幅图中讲3种zone的配图是错的吧?左边 physical-address space中绿色的部分“DRAM(3GB)”应该是“DRAM 896MB” 吧?